I’ve done a lot of travelling recently – mostly by train, but also one flight, which I feel guilty about (but I’ll get onto that later). And on these journeys I have on several occasions talked to the person sitting next to me. At some point in the conversation, they ask me what I do. And when I say I observe climate change, they light up and we have a deep conversation. Several of these serendipitous conversations have been with grandmothers, worried about the world their grandchildren are growing into. Our conversations go well beyond the science – although they want to know about the science too – and fundamentally they come down to ‘what can I really do?’
These conversations have been clarifying my own thinking about what society needs to change. This is not a subject I have any expertise on, so here I write in a personal, rather than professional, capacity. But it is a subject I think a lot about. Of course, there are many other resources on the practical options, and I’ll try to link to them later (although I’m too tired to search them all now). What I want to discuss here is a more general perspective.
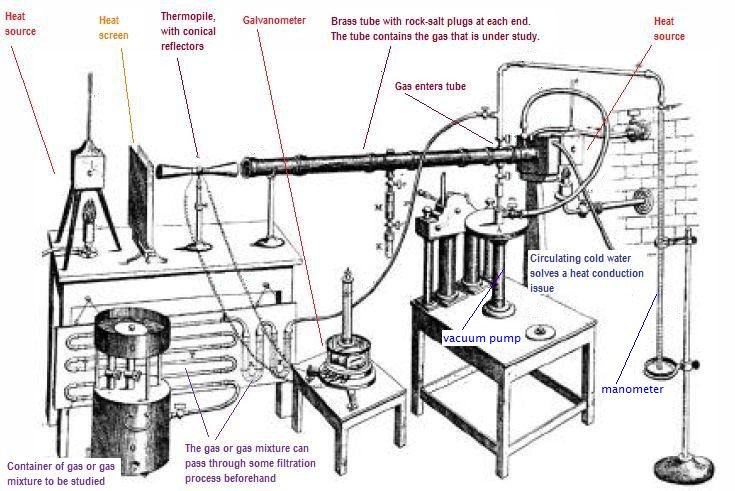
Climate change is real, and more serious than most people realise. Even if you consider yourself well-informed, you are probably underestimating the speed and scale of the changes that are coming (unless you’re panicking, or feeling like it’s too late and we’re all doomed, in which case you may have a different distortion). I have recently been to a large number of climate conferences – and I have found myself in tears during scientific presentations, especially one on melting glaciers in the Alps. The scientist presenting showed pictures of their measuring station in the Alps – and how their institute had been monitoring the glacier in the same spot for 150 years. This summer, the glacier broke off and their station disappeared forever. Something in the way that was presented, in the visual images, made me cry. But the other presentations were telling a similar story – rapid heating of the oceans, sea level rise displacing millions of people, ocean acidification, polar ice caps vanishing, ocean circulation patterns changing, rapid increase in the ferocity and frequency of storms, drought, heatwaves, and so on. We also have less time than we think. Governments are talking about 2050, but what we do in the next 5 years will have massive, long-term impacts – at the world’s current fossil fuel burning rate, we’ll reach 1.5 degC warming in 4-8 years. We need to stop using fossil fuels, now.
But this is terrifying, and most of us feel helpless. I feel helpless, too. But terror is not a good emotion for action – terror leads to our flight or fright response – we either ignore the danger, or we get angry. I fear that when scientists like me keep talking about the problem, and activists keep doing their stunts to force us all to take notice, we’re all reacting with a flight or fright response. (I do, however, understand why activists are doing their stunts and I am going to keep talking about the problem).
There are things we must do as individuals, things we do as communities and things we do as a society and through our governments. Each of us has a different set of background challenges, and a different set of skills and abilities – so we each have different responsibilities. How do we work out what our personal responsibilities are? I know some people who will take a perfectionist attitude. It is true that if we fairly share the remaining ‘carbon budget’ to get to 1.5 degC between the population of the Earth, then we cannot eat meat, chocolate, coffee or dairy products (produced as they are now) more than once or twice a month. We cannot fly, ever. We cannot own a car per family – we should be sharing our (electric or hydrogen, small) cars with our neighbours. We have to buy less stuff (electronics, clothes, …) , especially stuff with short lifespans. (I haven’t double checked all this, so treat details with caution – my point here is the principle, not the detail). Ideally we’d be generating our own electricity with our roof solar panels and capturing rainwater for flushing our toilets or growing our vegetables.
Those kinds of changes are hard. Sometimes impossible. I’m sure each reader (I think I get readers) will have read that previous paragraph with a combination of guilt, fear and perhaps anger (because you can’t do that) and pride (for the ones you are doing better than others). A perfectionist mindset hits other ‘ist’s. It is ableist (harder to do without a car if you are disabled), racist (harder to do without flights if you have family on another continent), classist (harder to make changes if you’re poor and if we stop buying things jobs are lost), pits city vs countryside (our country has a huge public transport issue outside a small number of big cities). And yet, it is needed. We’ve actually missed our chance to do this slowly and gently over a few decades – because of active, intentional misinformation campaigns in the last decade of the 20th century and the first decade of the 21st. Does that make you feel angry? It does me.
So, what can we do? The first thing I think we must recognise is that most change has to come from our governments and the decisions they make. The main problems are from the way society is structured – the choice of building materials, the way steel and concrete are manufactured, the way fossil fuels and sustainable energy, and different farming methods are taxed and/or subsidised, the accessibility of public transport, and availability of alternative options to cars and flying. We as individuals are not without influence (we can influence through our votes, our participation in democracy and/or activism, our influence in our jobs and even our choice of jobs, where our pensions are invested, …), but we need action at state levels.
Our individual actions are also important. Not so much because we actually as individuals have any significant impact on the planet, but because we as individuals can have a lot of impact on other people. We must look out for environmental tipping points because of the risks they pose to us, but we must also look out for social tipping points, because of the opportunities they provide. We’re social creatures and we all want to be doing what everyone around us is doing (think about covid mask wearing norms in different countries, and/or sectors within countries and how they tipped from (almost) ‘no-one’ to (almost) ‘everyone’ and back to (almost) ‘no-one’ as we followed laws and, more importantly, followed those around us. In my childhood bicycle helmet wearing was rare, now it’s very common here). When we change our behaviour, we influence those around us.
I think the hope society has, is in a non-linear growth of pro-environmental behaviour and choices. And in later blogs I want to explore that further. I’m also wondering about setting up some discussion forums – online and in person somewhere near Kingston/Teddington – next year to allow people to talk and ask questions. (If I have the energy, I’m going to discuss the importance of not burning out as individuals next).